NVIDIA Jetson Xavier NX 实现官方Jeston-inference深度学习样例
NVIDIA Jetson Xavier NX 实现官方Jeston-inference深度学习样例
一、jetson-inference相关项目组件的下载
首先附上官方提供的jetson_inference项目文件的Github仓库地址,大家可以自行前往下载
jetson-inference下载地址:https://github.com/dusty-nv/jetson-inference
另外,在该地址下包含详细的官方关于这个项目文件的相关介绍和使用方法,大家如果觉得我说的啰嗦,可直接前往该地址一步一步的安装调试。
还要多说一点的是,很多人也会选择直接在终端执行git操作进行克隆jetson-inference repo。但是因为同样的某些原因,我直接git操作,下载极其缓慢而且还会中断好多次,导致下载失败,所以我是选择自己单独将整个jetson-inference项目下载到本地进行解压。在这里给大家推荐一个可以加速下载GitHub上面文件(尤其是大文件)的方法----“码云”----,直接将要下载的GitHub文件fork到自己的仓库下,然后进入码云网站登录账号选择导入仓库,然后进行下载,可以到达正常的网线带宽下载速度,具体的操作流程大家可以去找一下相关的教程,总体来说操作还是比较简单的。
二、编译
1、在编译jetson-inference项目时需要用到 cmake,请确认系统上已安装 git 与 cmake,或者执行以下指令:
sudo apt install -y git cmake
(之前提前下载好的此步可省略)然后将 git 的代码复制一份到设备上
git clone https://github.com/dusty-nv/jetson-inference
2、接着进入该jetson-inference目录并取得代码更新版本
cd jetson-inference
git submodule update --init
3、然后创建build目录并进入,然后cmake
mkdir build
cd build
cmake ../
此时,按步骤执行到这一步的时候,问题就来了,由于这里的 cmake 会调用 CMakePreBuild.sh去下载很多预训练好的模型,但这些模型放在 nvidia.app.box.com 上面,同样的因为某些原因,我们下载这些东西会失败,在这里提供两种解决办法
PLAN A:
预先将相应的与预训练模型提前下载好,并放入到jetson-inference/data/networks目录下,同时将jetson-inference目录下的CMakePreBuild.sh里的关于下载模型 model downloader注释掉即可。关于下载预训练模型的方式,官方虽然想到了我们国内的原因给了我们镜像下载方式,链接如下:
https://github.com/dusty-nv/jetson-inference/releases
但是无解的是,仍然无法下载,所以我只能到处搜集了一些科学上网人士自己下载下来并贡献出来的模型文件,在此我也分享出来,但是模型文件并不是很全,就当给大家做一个参考吧,某盘下载链接如下:
链接:https://pan.baidu.com/s/1kjA4zj43szttZWkhDTMP6Q
提取码:kwhw
PLAN B:
针对某些原因我们不能直接下载官网模型的问题,有一些服务支持做的比较好的某宝Jetson板卡销售商家,会为购买过板卡的客户提供他们自己搭建的国内镜像下载网站,可以完美下载安装,我就是通过这种方式搞定的,简直爽歪歪,但是我也不好给大家公布出来,大家还是自己找找资源吧。
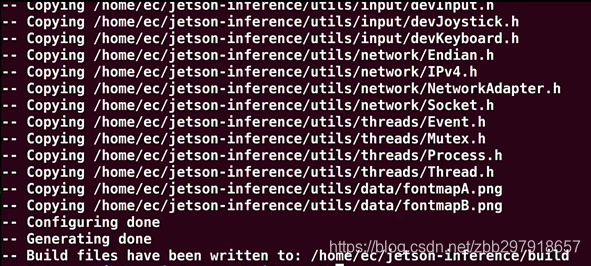
如果以上环境配置正确的话,cmake最后会出现下图最后一行“Build files have been written to: xxxxx/build” 的信息,否则就会出现错误信息。如果出现错误,建议把 build 目录产生的内容全部清空(在 build 目录下执行 rm -rf *),然后重新 cmake …/
4、接着就可以继续往下执行
# 这里的 make 不用 sudo ,后面 -j4 使用 4 个 CPU 核同时编译,缩短时间
make -j4
5、如果编译正确的话,就可以继续往下执行
# 这里 make install 因为要写入系统目录去,因此需要 sudo
sudo make install
sudo ldconfig
如果以上的各部分编译都正确的话,在jetson-inference/build/aarch64目录下的文件结构如下
|-build
\aarch64
\bin where the sample binaries are built to
\networks where the network models are stored
\images where the test images are stored
\include where the headers reside
\lib where the libraries are build to
到此,整个的jetson-inference就算完美的配置完成了。
三、测试
在这里我以image recognition做详细的步骤介绍,其他的Object Detection、Semantic Segmentation都与此类似,操作步骤不做详细介绍。
1、图片检测
首先,必须确保你的终端是在aarch64/bin目录下打开的,否则你需要切换到该目录下
cd jetson-inference/build/aarch64/bin
接着,官方为大家提供了C++版和python版的操作样例,针对想要使用不同的版本的终端输入指令如下
C++版:
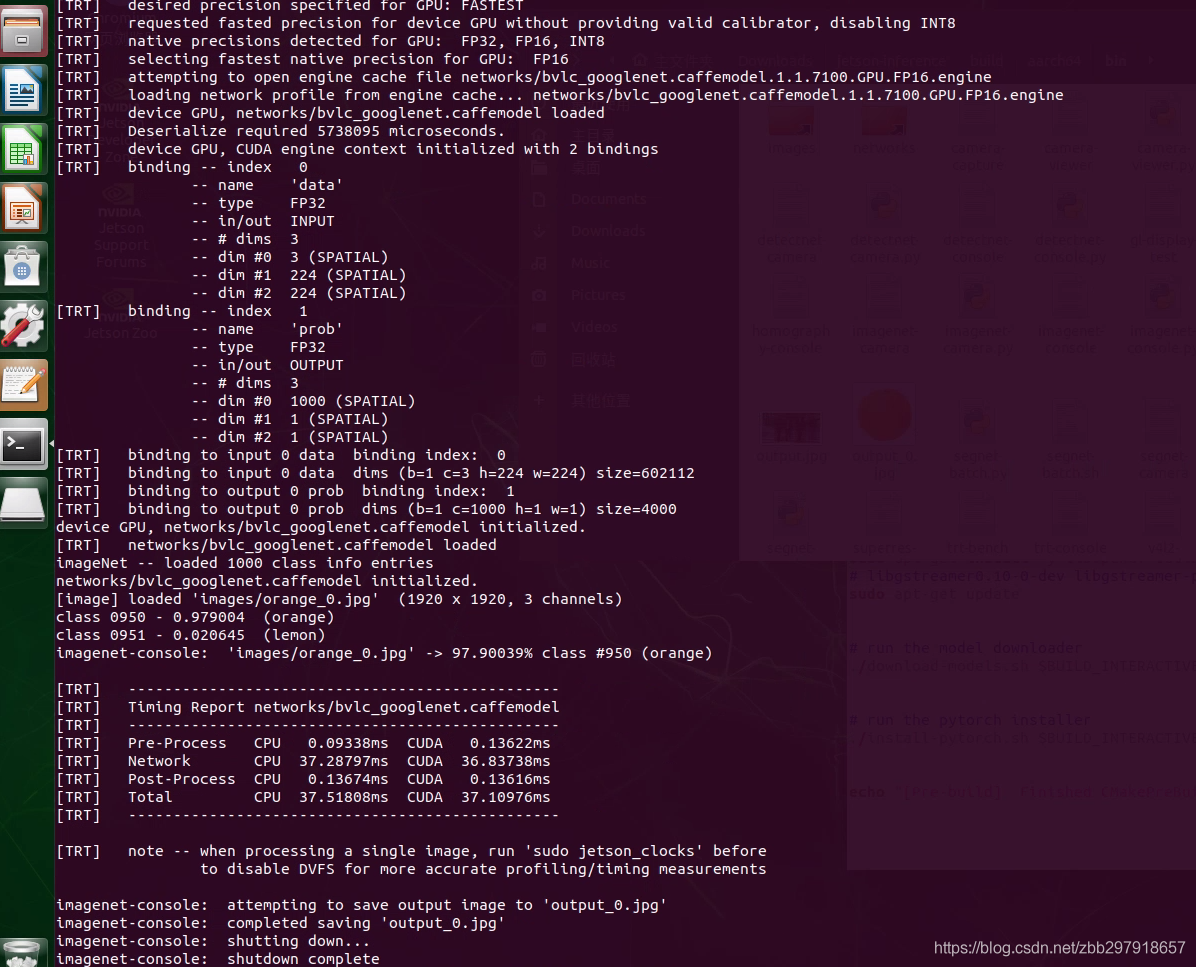
./imagenet-console --network=googlenet images/orange_0.jpg output_0.jpg # --network flag is optional
python版:
./imagenet-console.py --network=googlenet images/orange_0.jpg output_0.jpg # --network flag is optional
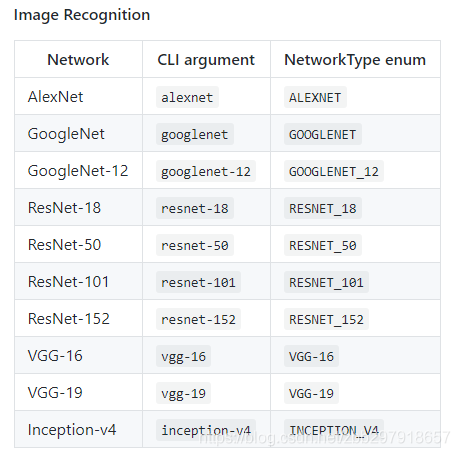
这里默认调用的网络模型是 googlenet,如果想要换成其他的模型,需要更改指令中开始部分的imagenet、detectnet或者segnet,以及其后包含的的--network=后的网络名称即可(前提是你已经下载好这些模型),官方样例给出的一些image recognition预训练模型如下
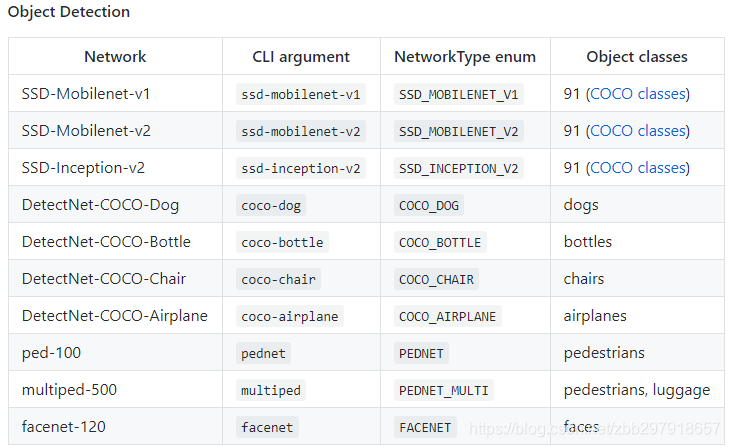
Object Detection的一些预训练模型如下
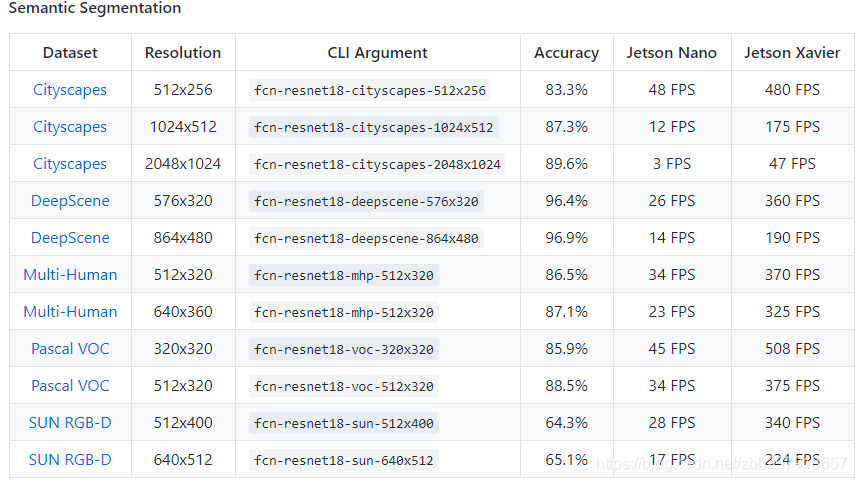
Semantic Segmentation的一些预训练模型如下
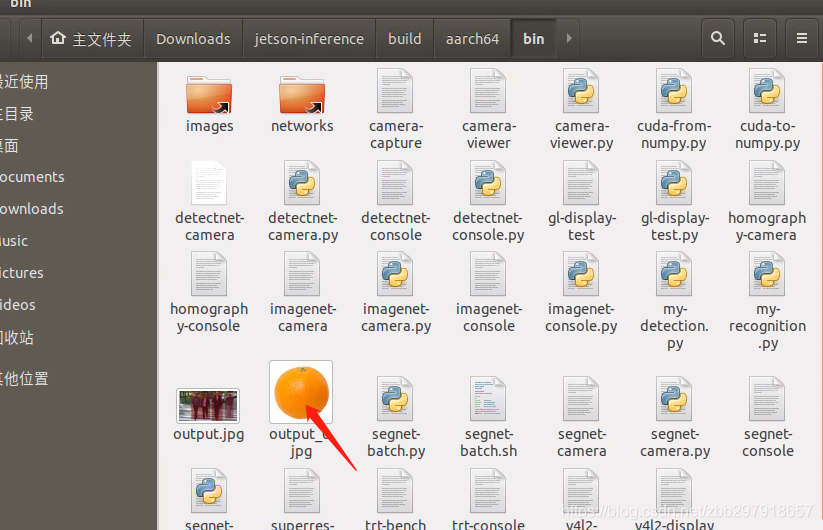
此外,输入要检测的图片也可根据自己想法进行更改,不做更多说明。另外当你第一次运行上述指令的时候,TensorRT需要花费一些时间对网络进行优化,因此整个执行过程可能时间比较长,之后再执行的时候时间相对会比较短,我们可以在bin目录下查看输出的结果图片。
2、摄像头实时视频检测
在进行视频检测之前,需要确定一下自己的视频输入的方式,是通过USB视频输入还是MIPI CSI的输入方式,还要通过以下指令确定一下摄像头的设备号
ls /dev/video*
另外还要了解以下视频输入的分辨率大小,通过安装V4L2可以确定USB摄像头的视频输入参数,终端输入指令如下
sudo apt-get install v4l-utils
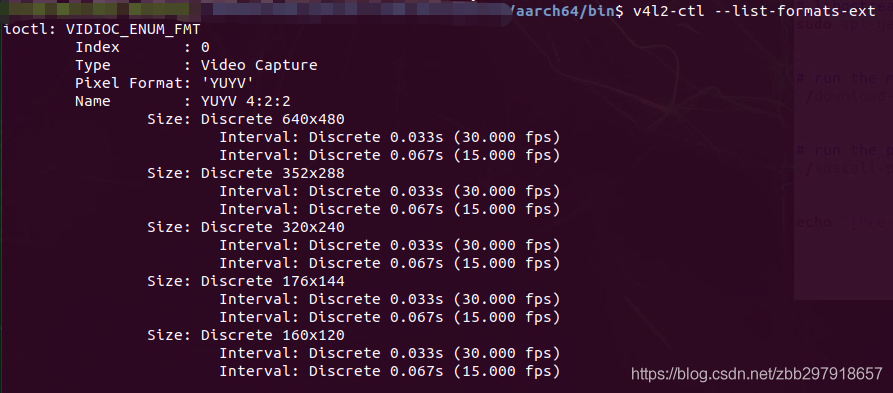
终端输入以下指令即可看到摄像头输入视频的相关信息
v4l2-ctl --list-formats-ext
接着,类似检测图片一样的操作,官方也为大家提供了C++版和python版的操作样例,针对想要使用不同的版本的终端输入指令如下
C++版:
./imagenet-camera --network=resnet-18 --camera=/dev/video0 --width=640 --height=480
python版:
./imagenet-camera.py --network=resnet-18 --camera=/dev/video0 --width=640 --height=480
默认情况下是使用的googlenet,输出的分辨率默认情况下,USB摄像头为640x480,MIPI CSI为1280x720。指令后面的参数也可以根据自己的情况进行更改。
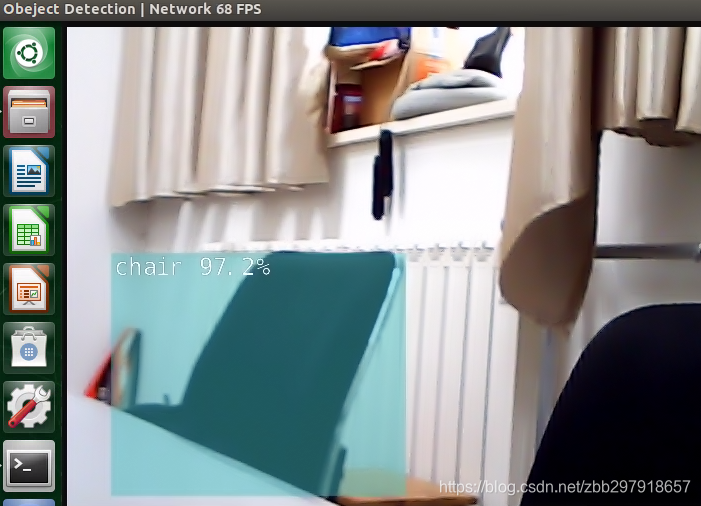
最后,给大家附上,python代码脚本完美运行ssd_mobilenet_v2进行实时视频检测
import jetson.inference
import jetson.utils
net = jetson.inference.detectNet("ssd-mobilenet-v2",threshold=0.5)
camera = jetson.utils.gstCamera(640,480,"/dev/video0")
display = jetson.utils.glDisplay()
while display.IsOpen():
img,width,height = camera.CaptureRGBA()
detections = net.Detect(img,width,height)
display.RenderOnce(img,width,height)
display.SetTitle("Obeject Detection | Network {:.0f} FPS".format(net.GetNetworkFPS()))
直接在终端执行 python3 my_object_detection #后面为脚本文件名 即可运行。
到此,这个官方的jeston-inference算时介绍完了,大家可以根据自己的情况做进一步的探索。
原文:https://blog.csdn.net/zbb297918657/article/details/106432773